My first thought was to create some non-trivial web application, maybe with some new UI concepts to browse the data. Then came the idea.
I'm often using Windows Explorer to organize my files using into directories. I could use standard jpg files as placeholders -- one jpg file for each website. Then, in the jpg's metadata, I could store the url.
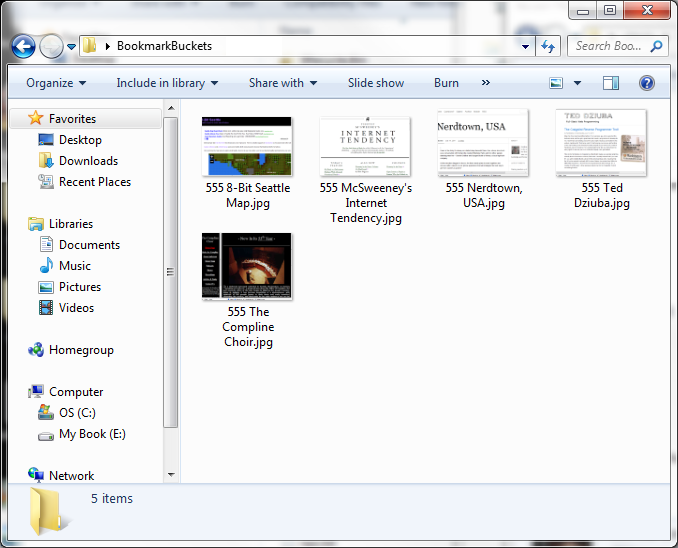
Each bookmark is represented by a .jpg image that is a screenshot of the website. The name of the file is the name of the site. The url is stored in exif metadata within the image, (crucially, exif is a standard format that can be read by many programs, for data longevity). Now 90% of the work is done for me - navigating, renaming, moving into folders. Syncing between machines can be done with Dropbox or Skydrive. Exporting to plain text can be done with a simple Python script. As a finishing touch, I wrote a little C# app so that you can quickly launch the webpage by drag/dropping the .jpg into the "bookmarkbuckets" window.
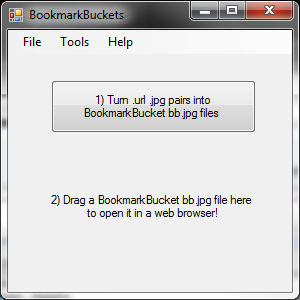
Here are the steps I take:
1) Start with a plain text file with urls and titles on alternating lines, or a folder of .url files.
2) A lnzscript script opens each url in a browser and takes a screenshot as a .jpg image.
3) BookmarkBuckets alters the .jpg image to add the URL in exif data. It also adds the original html title into the jpg metadata.
Now, these .jpg files are all that's needed. I can rename and recategorize as needed.
To open the corresponding webpage, drag the .jpg and drop it into the "bookmarkbuckets" window.
(Bookmark buckets can also export all links back to a tab-delimited file).
It's worked well for me.
I wasn't able to find an already-existing solution that would have:
- Thumbnail screenshots of the webpage
- Easy to organize bookmarks into folders, not just tags
- Ability to export bookmarks and titles to simple plain-text
- Ability to sync bookmarks between machines
- Quickly navigate, rename, open, delete
Update: I've added the source to GitHub here under the GPLv3.
Postscript:
I wrote in 2007 that I used bookmarks in 3 different ways:
1) a shortcut to a commonly accessed page
2) a way to remember a less-commonly accessed page
3) a way to put aside a webpage in order to return to it later
These have changed over the past few years...
Shortcuts like the awesome bar, and Google instant have all but eliminated the need for 1.
Apps like instapaper and readitlater address 3.
I'll have to keep working on Bookmarkbuckets so that it's the most effective way to solve the second problem.